
Für die Erklärung, wie Sprachassistenten funktionieren, muss erst einmal zwischen den Begriffen Sprachassistent und Smart Speaker unterschieden werden: der eigentliche Sprachassistent ist eine Software im Rechenzentrum des Anbieters (Amazon, Google), während die Smart Speaker die Geräte sind, die häufig in den Haushalten den Zugriff auf diese Sprachassistenten ermöglichen. Sprachassistenten-Systeme funktionieren also als verteilte Systeme.
Wir zeigen Ihnen im Folgenden – nach einem Kurzüberblick – einerseits die grundlegende Funktions-Architektur des Sprachassistenten-Systems und geben danach einen Überblick, wie genau ein Dialog mit Alexa oder den Google Assistant abläuft.
Wie funktionieren Sprachassistenten – kurz gesagt
- Aufnahme der Umgebung mit Mikrofonen und Erkennung des Aktivierungswortes (typischerweise ‚Alexa‘ bzw. ‚Ok Google‘)
- Prüfung auf lokale Verarbeitbarkeit der Anfrage (eher selten der Fall)
- Streaming des nach dem Aktivierungswort Gesagten an die Sprachassistenten-Software in der Cloud des Anbieters
- Audio-Verarbeitung (z. B. Trennung Sprache von Hintergrundgeräuschen sowie Worterkennung)
- Inhaltliche Analyse: Ermittlung des Intents (der Absicht) und der Slots (der zugehörigen Parameter) im erkannten Text
- Ausführung der eigentlichen Verarbeitung (ggf. in einer Voice App: Skill oder Action) und Generierung des Antworttextes bzw. von Smarthome-Steuerbefehlen
- Ausgabe der Antwort bzw. Steuerung der Smarthome-Geräte
Soweit die Kurzform. Und jetzt im Folgenden nochmal etwas ausführlicher.
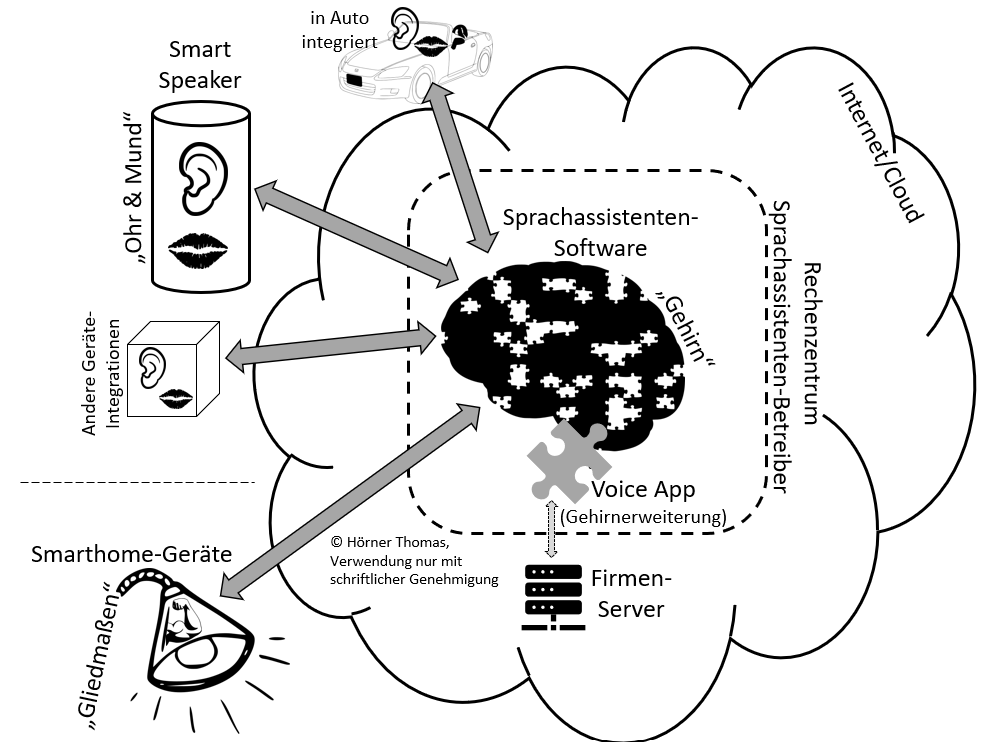
Die Grund-Architektur von Sprachassistenten
Für das Funktionieren von Sprachassistenten gibt es mindestens zwei Orte, an denen es Funktionalitäten geben muss: das Gerät vor Ort und die Software in der Cloud. Oft kommt noch ein dritter Ort hinzu: die Software eines dritten Unternehmen, das Voice Apps (Skills, Actions) betreibt.
Sprachassistenten-Funktion vor Ort
Am Ort der Nutzung von Sprachassistenten gibt es ein Gerät, das die Mensch-Maschine-Schnittstelle zur Verfügung stellt. Das sind oft die Smart-Speaker Amazon Echo oder der Google Home oder auch einfach die Google Assistant App auf einem Smartphone. Es können aber auch andere in Haushaltsgeräte oder in das Auto integrierte Schnittstellen sein. Diese Schnittstellen bestehen im Wesentlichen aus Mikrofonen, Lautsprechern und etwas integrierter Elektronik.
Bildlich gesprochen sind die Smart Speaker und andere Geräte vor Ort die Ohren und Münder der Sprachassistenten.
Sprachassistenten-Funktion in der Cloud
Die wichtigsten Funktionen eines Sprachassistenten finden sich in der Cloud bzw. im Rechenzentrum des jeweiligen Anbieters (bei Alexa in der Amazon Cloud, bei Google Assistant in der Google Cloud). Die Smart Speaker vor Ort benötigen daher immer eine Verbindung zu dieser Cloud-Software, um die eingesprochenen Anfragen dort verarbeiten und Antwort-Dialoge ermitteln zu lassen. Deshalb muss das Gerät vor Ort auch immer mit dem Internet verbunden sein, wenn es genutzt werden soll.
Bildlich gesprochen ist diese Cloud-Software das eigentliche Gehirn des Sprachassistenten, das die Anfragen verarbeitet.
Funktionen in Dritt-Anbieter-Apps
Die Sprachassistenten-Software in der Cloud bietet schließlich Software-Schnittstellen, über die sie Anfragen an die Software Dritterzur dortigen Verarbeitung weiterreichen kann (z. B. durch die eigene Programmierung eines Unternehmens). Diese so genannten Voice Apps werden angesprochen, wenn ein Nutzer „Alexa, frage (App-Name) …“ bzw. „Ok Google, rede mit (App-Name)…“ sagt. Auf diese Weise können Unternehmen eigene Dialoge integrieren, z. B. für Voice Marketing.
Diese Software-Ergänzungen in Form von Voice Apps können entweder auf den eigenen Servern des Voice-App-Anbieters liegen oder in gemietetem Rechnerplatz der Cloud.
Will man im oben begonnenen plaktiven Bild eines Sprachassistenten verbleiben, wären diese Voice Apps Gehirn-Erweiterungen, die diesem neue Funktionen hinzufügen.
So funktioniert ein Sprachassistenten-Dialog
Wie läuft ein Dialog mit einem Sprachassistenten ab? Wie funktioniert dieser technisch?
1. Schritt: Aktivierung erkennen
Die Smart Speaker (oder die App auf dem Smartphone bzw. andere Geräte vor Ort) sind nicht dauerhaft mit der Sprachassistenten-Software verbunden. Sie streamen auch nicht laufend und durchgehend alles ins Internet oder zu Amazon/Google, was in ihrer Umgebung zu hören ist.
Die Mikrofone nehmen ihre Umgebung allerdings durchaus laufend auf und leiten diese Aufnahmen an die Elektronik im Gerät vor Ort. Diese prüft, ob das Aktivierungswort (bei Amazon „Alexa“, bei Google „Ok Google“) gefallen ist. Er wenn dieses Aktivierungswort erkannt wurde, startet eine Aufnahme und es folgen die weiteren Schritte inklusive dem Streaming ins Netz.
Ist das Aktivierungswort nicht gefallen, wird die Aufnahme des Mikrofons nach wenigen Sekunden wieder verworfen (gelöscht) und es erfolgt keine weitere Aktivität.
2. Schritt: Prüfung, ob lokale Verarbeitung möglich
Die Elektronik des Smartspeakers prüft jetzt gegebenenfalls, ob eine sehr einfach Anfrage vorliegt, die direkt vor Ort und ohne Verbindung zur Software in der Cloud beantwortet werden kann. Das wäre beispielsweise der Fall, wenn Alexa oder Google Assistant nach Uhrzeit oder Datum gefragt werden.
In frühen Versionen der Smart Speaker gabe es diesen Schritt einer lokalen Verarbeitung überhaupt nicht und selbst einfachste Anfragen wurden (und werden auch heute meist noch) zur Bearbeitung in die Cloud gestreamt. Je moderner die Geräten allerdings werden, desto eher ist doch bereits in der Elektronik vor Ort eine grundlegende Sprach- und Intent-Erkennung integriert, so dass solch einfach Anfragen direkt vor Ort bearbeitet lassen.
3. Schritt: Streaming der Anfrage in die Cloud
War das Aktivierungswort erkannt worden (und die Anfragen kann nicht vor Ort verarbeitet werden – also in den meisten Fällen) wird das Aufgenommene als Audio-Datei über das Internet an die Sprachassistenten-Software in der Cloud des jeweiligen Herstellers geschickt. Deshalb braucht es auch unbedingt eine Internetverbindung per WLAN oder Mobilnetz.
4. Schritt: Verarbeitung der Anfrage im Sprachassistenten
In der eigentlichen Sprachassistenten-Software angekommen beginnt die entscheidende Verarbeitung. Diese besteht aus mehreren Stufen: der Spracherkennung, der Ermittlung des eigentlichen Inhalts der Anfrage und schließlich der Abarbeitung der Anfrage sowie die Ermittlung der auszugebenden Antwort.
4a. Spracherkennung
Aus den durch das Mikrofon aufgenommenen und über das Internet gestreamten Audio-Files müssen jetzt die gesprochenen Worte extrahiert werden. Dazu werden verschiedene Verarbeitungsschritte ausgeführt: die eigentliche Sprachinformation wird vom Hintergrundgeräuschen als auch von Raumhall getrennt (Speech Signal Enhancement, SSE und Beamforming) sowie eine Worterkennung innerhalb des Audiofiles durchgeführt.
Aus den erkannten Worten muss dann im Rahmen in einer weiteren Verarbeitung zum inhaltlichen Verstehen eine Textanalyse durchgeführt werden. Es gilt, diejenigen Worte zu erkennen, die die eigentliche Absicht des Nutzers wiederspiegeln und diese entscheidenden Worte von sonstigen Textteilen zu trennen.
Am Ende der Verarbeitung wurde die konkret Absicht (englisch: Intent) in der Aussage des Nutzers extrahiert sowie ggf. die zu diesem Intent gehörigen Parameter (‚Slots‘ genannt) ermittelt.
Ein Beispiel: Eine Nutzerin sagt „Alexa, wie ist aktuell das Wetter in Hamburg?“ oder sie sagt „Alexa, sag mir das Wetter derzeit in Hamburg?“ – dann ist in beiden Fällen, trotz der unterschiedlichen Formulierung, der gleiche Intent zu erkennen: nämlich das Wetter zu erfahren. Die Slots sind einerseits die Stadt (hier: Hamburg) und andererseits der Zeitraum (hier: zum jetzigen Zeitpunkt).
4c. Abarbeitung der Anfrage & Ermittlung der Antwort
Ist der Intent einmal ermittelt, kann die Anfrage konkret bearbeitet werden. Im Falle des obigen Beispiels würde Alexa bzw. der Google Assistant auf eine Wetter-Datenbank zugreifen und dort die Daten zur aktuellen Wettersituation abrufen. Analog würde das bei anderen Anfragen (Rechenaufgabe, Begriffserklärungen, etc.) erfolgen.
Eine Besonderheit, die gerade für das Marketing mit Sprachassistenten von Bedeutung ist, gibt es an dieser Stelle: sagt der Nutzer „Alexa, frage (App-Name) …“ oder „Ok Google, rede mit (App-Name) …“ so wird die Sprachassistenten-Software die Anfrage nicht direkt selbst bearbeiten. Vielmehr werden der Intent sowie die ggf. zugehörigen Slots an ein externes Programm zur Bearbeitung weiter gereicht: die so genannten Voice Apps (Amazon Skills bzw. Google Actions) übernehmen die Verarbeitung. Unternehmen können auf diese Weise also in eigener Software den Dialog steuern und abarbeiten.
Am Ende der Verarbeitung wird dann üblicherweise ein konkreter Text zusammen gestellt, der als Antwort für Nutzer bzw. Nutzerin gedacht ist, z. B. „In Hamburg scheint derzeit die Sonne bei 24 Grad“. Hat eine Voice App die Anfrage bearbeitet, wird eben dieser Text (für IT-ler: als String) an die Alexa-Software bzw. den den Google Assistant übergeben.
Alternativ oder ergänzend zu einer solchen Sprachantwort – durch den Sprachassistenten direkt ober in einer Voice App – aber auch der Steuerbefehl für ein Smarthome-Gerät entstehen.
4d. Antwort schicken und ausgeben
Liegt das Ergebnis der Verarbeitung einmal fest, muss diesen jetzt nur noch ausgegeben werden. Dazu wird die festgelegte Textantwort an das benutzte Gerät (Amazon Echo, Google Home oder jedes ursprünglich angesprochene Gerät) zurück geschickt und dort über die Lautsprecher ausgegeben.
Ist auch ein Smarthome-Steuerbefehl aus der Verarbeitung hervor gegangen, wird dieser an das betreffende Gerät per Internet (im letzten Schritt meist WLAN) übertragen.
FAQ zur Funktion von Sprachassistenten
So läuft die Nutzung von Sprachassistenten technisch ab:
1. Warten auf das Aktivierungswort (z.B. „Alexa“, „Hey Google“, …)
2. Streaming des danach gesagten an die Cloud (zur eigentlichen Sprachassistenten-Software, z.B. bei Amazon, Google, …)
3. Audio wird in Text und dann in Steuerbefehle umgesetzt
4. Bearbeitung der Anfrage, a) durch Sprachassistent selbst oder b) Übergabe der Kontrolle an Programmierung einer Voice App
5. Rückgabe des Antworttextes an das Frontent, z.B. den Smartspeaker
Nein. Der Sprachassistent wartet zuerst nur auf das Aktivierungswort (z.B. „Alexa …“ o. „Hey Google …“). Erst danach wird alles Gesagte ins Internet (genauer: zur Sprachassistenten-Software in der Cloud von Amazon, Google, …) übertragen, bis eine längere Sprechpause die Übertragung wieder unterbricht.
Dazu muss man eine Voice App (Amazon Skill, Google Action …) programmieren. Diese wird mit „Alexa, frage (Voice-App-Name) …“ bzw. „Hey Google, rede mit (Voice-App-Name) …“ angesprochen. Dann hat man mit der eigenen Programmierung die Dialoge des Sprachassistenten unter Kontrolle.
Fast gar nicht. Da die Verarbeitung der Sprache des Nutzers sehr aufwändig ist, muss diese in großen Rechenzentren erfolgen, deshalb muss jede Anfrage direkt über das Internet übertragen werden. Ohne Internet kann ein Sprachassistent nur sehr rudimentäre Anfragen (z.B. nach der Uhrzeit) beantworten.
Guten Tag,
ich muss eine Seminararbeit zum Thema Sprachassistenten schreiben und wollte mich erkundigen ob ich die Informationen und Bilder ihrer Website nutzen darf.
Grüße Philip Arnold